

























On sort des sentiers battus avec une question qui nous taraude depuis plusieurs années : Est-ce que Facebook et compagnie nous écoutent à notre insu, via nos smartphones, pour mieux cibler leurs publicités ? Vivant au Japon depuis de nombreuses années, j’ai observé une recrudescence des hasards « douteux » devenus beaucoup trop nombreux pour être de simples coïncidences. J’ai donc décidé de documenter la chose…
Dans les rapports humains, celui qui contrôle la « zone d’incertitude » possède le pouvoir. En matière d’écoute commerciale des discussions privées, elle est officiellement non-reconnue et niée par les géants du secteur. Cette zone d’incertitude représente pourtant une manne potentielle pesant plusieurs milliards de dollars, tant l’information est devenue le véritable pétrole du monde moderne. Peut-on décemment croire qu’aucun spécialiste du secteur de la revente de données ne touche à cette manne de profits potentiels alors même que les GAFAM multiplient les scandales ?
Nous sommes très nombreux à avoir eu cette expérience au moins une fois. Nous discutons simplement avec des amis ou notre famille quand, quelques heures plus tard, notre fil d’actualité nous affiche une publicité sur une thématique abordée à l’oral ! Cette coïncidence se répète parfois sur des sujets très variés – pas nécessairement en rapport avec nos préférences personnelles – qui n’ont jamais impliqué de recherche sur un quelconque moteur. Pour beaucoup d’entre nous, il n’y a plus aucun doute : les GAFAM nous écoutent en secret pour mieux cibler leur publicité via leurs outils similaires à Siri ou OK Google qui leur permettent déjà de nous écouter en permanence, même quand nous n’utilisons pas notre smartphone.
Mentir, mentir, mentir, puis s’excuser…
Longtemps, cette intuition a été conspuée dans les médias classiques qui se rallient volontiers aux déclarations des géants du domaine. Ceux-ci nient fermement écouter leurs clients dans un cadre commercial. À l’été 2019, Facebook avait finalement admis écouter certaines conversations d’usagers à leur insu, mais dans le but de vérifier la qualité de transcription de leur logiciel ! Il faut donc les croire sur parole : même si la chose est techniquement possible, ils ne le feraient pas dans un but commercial. On croirait presque un instant que les entreprises les plus puissantes au monde font dans l’humanitaire. Selon la version officielle, à ce jour, Facebook et les géants du web ne nous écoutent pas pour nous vendre des produits adaptés à nos envies. Penser que les entreprises de l’information puissent utiliser nos données audio serait une simple théorie du complot, au pire, des hasards ou de simples coïncidences… Nous n’y croyons pas un instant tant le phénomène est devenu récurrent et malsain.
« Arrêtez de me montrer des publicités de choses dont je viens juste de parler. »

Pour ceux qui ne veulent pas prendre les paroles des multinationales les plus puissantes du monde comme du pain béni, il reste à se forger un avis personnel sur les expérimentations disponibles et sa propre expérience. À ce titre, on trouve tout et son contraire sur le web. Tout d’abord, de nombreux internautes ont voulu démontrer cette réalité en piégeant leur ordinateur ou smartphone avec un protocole expérimental très simplifié mais efficace.
C’est notamment le cas du Youtubeur américain Mitchollow qui a réalisé un test en direct-live sur Youtube afin d’éviter les fraudes. Le protocole était simple. Vérifier d’abord un panel de publicités sur différentes pages. Ensuite, parler d’un thème déterminé et neutre durant plusieurs minutes en insistant sur le fait de vouloir acheter cet objet. Puis mettre à jour différentes pages sur internet et vérifier les nouvelles publicités. Dans le cas de Mitchollow, son thème « neutre » était les jouets pour chien. En effet, le youtubeur n’a pas de chien, ce qui limite les erreurs liées à un profiling passé des algorithmes classiques. Surprise, il découvrira de nombreuses publicités visant les propriétaires de chiens. Depuis, l’expérience à été menée de nombreuses fois par différents youtubeur avec des résultats clivants. Chez certains, le phénomène est manifeste, pas chez d’autres… On ignore à ce jour ce qui détermine qu’un utilisateur est écouté ou non, à quel moment de la journée, pour quelle période de temps, selon quels critères. On peut supputer que – si l’écoute est réelle – ceux qui en sont à l’origine veulent nécessairement préserver un maximum de temps le mystère – contrôler la zone d’incertitude – notamment pour maintenir son avance stratégique sur les parts de marché de la revente d’informations.
Wandera au secours des GAFAMS
À décharge, un test pratique « sous contrôle » a été réalisé par un bureau d’étude privé. Celui-ci va balayer des centaines de tests indépendants des utilisateurs. Les ingénieurs de la société Wandera ont donc mené une expérimentation assez simpliste. 2 téléphones (Android/iPhone) ont été placés dans une pièce où des sons de publicités pour de la nourriture pour chiens et chats tournaient en boucle. Pas de test en situation réelle donc. 2 autres téléphones étaient placés dans une pièce silencieuse. Ces chercheurs n’ont trouvé aucune publicité en rapport avec la nourriture animale sur les différents téléphones. Selon la conclusion officielle, il n’y a pas de différence d’utilisation des données transférées entre les différents téléphones. Pourtant, leur propres données indiquent l’inverse à l’échelle du KB (1MB=1000KB). Deux applications indiquent envoyer davantage de données sur le réseau dans la pièce avec les publicités que dans la pièce silencieuse. Mais les quantités de données ont été jugées négligeables pour la société informatique. De manière consciente ou non, Wandera a choisi le MB pour comparer les données échangées. Pourtant, en KB, les données offrent une autre lecture.

Ainsi, pour Facebook, 190KB de données ont été envoyées et 340KB pour Instagram. Des quantités amplement suffisantes pour transférer une petite base de données de quelques milliers de mots tout de même. Mais en dépit de ces données, Wandera conclut envers et contre tout qu’aucun échange significatif de données n’a pu être détecté… Une conclusion interpellante contredite par leurs propres résultats. Quant à savoir pourquoi le test n’est pas concluant au niveau de l’affichage des données, c’est le protocole même du test qui est à questionner : non seulement il s’agit de sons publicitaires préenregistrés – ce qui constitue le discours d’une offre, pas d’une envie d’un consommateur naturel – mais en plus les téléphones étaient « neutres », donc sans profil utilisateur enregistré potentiellement ciblé par une marque (chaque utilisateur possède une sorte de profil web qui s’enrichit avec le temps). Ce sont ces profils qui valent de l’argent sur le marché de l’information. Beaucoup de médias ont une fois encore pris la défense des GAFAMS sur base de ce test privé jugé « irréfutable » et pourtant truffé de contre-sens et d’approximations.
Sur le graphique suivant, basé sur les données de Wandera, on constate une fois encore que les données envoyées dans la pièce avec publicité sont largement supérieures sous iOS (moins évident sur Android) bien qu’on reste sous le seuil du MB. En particulier concernant Facebook qui utilise jusqu’à 575 KB de données. C’est sur cette plateforme que nos tests auront lieu.
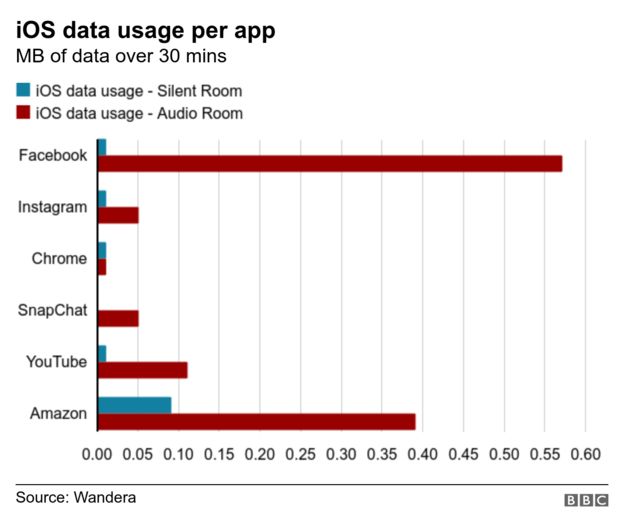 L’entreprise ayant réalisé ce test a donc sciemment décidé de ne pas prendre en considération ces données, les jugeant toutes insignifiantes sans distinction. L’erreur – volontaire ou non – est évidemment de faire croire que ce sont les sons qui seraient exportés par les logiciels, ce qui impliquerait effectivement des transferts en MB beaucoup plus importants. La technologie même de la reconnaissance vocale démontre qu’il n’est pas nécessaire d’envoyer des sons pour que le logiciel reconnaisse des mots en vue de s’activer ou de les retranscrire par écrit. En effet, un programme peut travailler en local et transformer les mots en données textuelles. Techniquement, il est assez primitif que l’analyse en temps réel des mots prononcés soit programmée pour retenir certains mots commercialement déclencheur d’une action : « aimer », « acheter », « avoir envie », etc.. Chaque déclencheur peut archiver très simplement des mots clés associés dans une même phrase dans un fichier crypté simplifié qui sera envoyé sur le serveur une fois connecté. Une telle base de donnée peut être à ce point simple qu’elle ne pèserait qu’à peine quelques KB pour des milliers d’informations stratégiques, de quoi passer totalement inaperçue sur le réseau.
L’entreprise ayant réalisé ce test a donc sciemment décidé de ne pas prendre en considération ces données, les jugeant toutes insignifiantes sans distinction. L’erreur – volontaire ou non – est évidemment de faire croire que ce sont les sons qui seraient exportés par les logiciels, ce qui impliquerait effectivement des transferts en MB beaucoup plus importants. La technologie même de la reconnaissance vocale démontre qu’il n’est pas nécessaire d’envoyer des sons pour que le logiciel reconnaisse des mots en vue de s’activer ou de les retranscrire par écrit. En effet, un programme peut travailler en local et transformer les mots en données textuelles. Techniquement, il est assez primitif que l’analyse en temps réel des mots prononcés soit programmée pour retenir certains mots commercialement déclencheur d’une action : « aimer », « acheter », « avoir envie », etc.. Chaque déclencheur peut archiver très simplement des mots clés associés dans une même phrase dans un fichier crypté simplifié qui sera envoyé sur le serveur une fois connecté. Une telle base de donnée peut être à ce point simple qu’elle ne pèserait qu’à peine quelques KB pour des milliers d’informations stratégiques, de quoi passer totalement inaperçue sur le réseau.
Pour un profane, la chose peut sembler compliquée ou floue. En pratique, rien n’est plus simple à réaliser du point de vue technique tant les outils de détection vocale sont déjà efficaces et performants. La technique existe donc. Les algorithmes modernes sont assez maîtrisés aujourd’hui pour mettre en pratique un tel archivage de mots dans une petite base de donnée cryptée. La véritable question est de pouvoir confirmer ou non si les géants de l’information ont déjà passé ce cap et réalisent des tests pratiques chez les utilisateurs depuis quelques temps. À ce jour, il faut comprendre que les seuls en mesure de confirmer ou d’infirmer l’usage illégal de ces données personnelles sont les employés des entreprises du numérique qui profitent de ces pratiques d’écoute et en protègent le secret.

Test pratique et autres coïncidences douteuses
Attention : ce qui suit n’est pas une expérience scientifique ! Depuis notre téléphone personnel, nous avons décidé de traquer les « coïncidences » troublantes après chaque soirée où de longues discussions ont lieu sur une durée d’un an. L’objet est de réaliser un cas pratique sans chercher à provoquer le phénomène, ce qui diffère lourdement avec les tests actuels (officiel ou non). Il faut y voir une forme d’observation participante comme pratiquée en sociologie. L’observation se fera uniquement sur Facebook où les échanges de micro-données ont été observés.
Pour qu’un cas soit pris en considération et validé, il y a des règles élémentaires que nous avons décidé de respecter :
1. L’objet commercial n’a pas pu être anticipé par un algorithme tiers.
2. Ne pas être connecté sur le réseau d’un ami ou d’un proche.
3. N’avoir fait AUCUNE recherche associée à l’objet commercial proposé avant.
4. Ne pas utiliser Siri, Alexa et OK Google de tout le temps de l’opération.
5. Ne pas chercher à provoquer le phénomène (contrairement aux tests réalisés sous contrôle jusqu’ici).
6. L’objet commercial doit être affiché dans les 24 heures où l’exemple n’est pas probant.
7. L’objet commercial déterminé ne revient pas, ce qui confirme son caractère temporel et spécifique relatif au besoin du consommateur exprimé verbalement à l’instant T.
8. Le fait d’être en ligne ou non lors de l’écoute n’est pas important, le traitement de la reconnaissance vocale pouvant être réalisé et archivé en local pour être envoyé ultérieurement.
Selon cette charte, voici une sélection de coïncidences troublantes observées dans notre vie privée pendant la période 2018/2019. NB : les conversations ont eu lieu le plus souvent en anglais. Les cas ci-dessous ne sont qu’un échantillon représentatif du phénomène parmi une trentaine de cas.
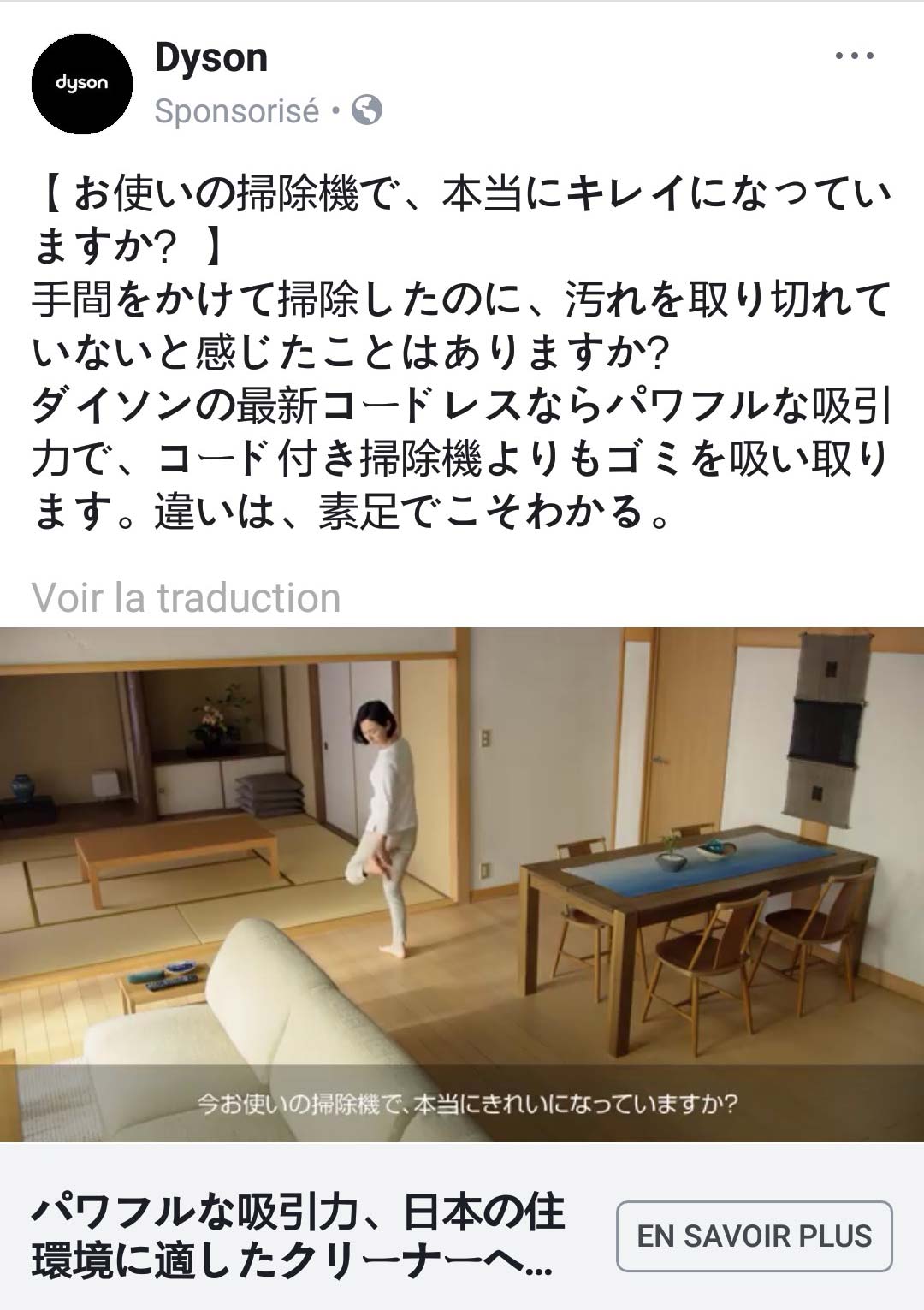
Peu de temps après avoir changé d’appartement au Japon, nous parlions avec ma compagne d’acheter un aspirateur performant. Peut-être un Dyson. Les jours suivants, cette publicité pour un aspirateur Dyson s’est faite récurrente. N’ayant pas réalisé de recherche internet pour un appartement ni un nouvel aspirateur, la coïncidence temporelle nous a semblé troublante. Ce n’est que le début…
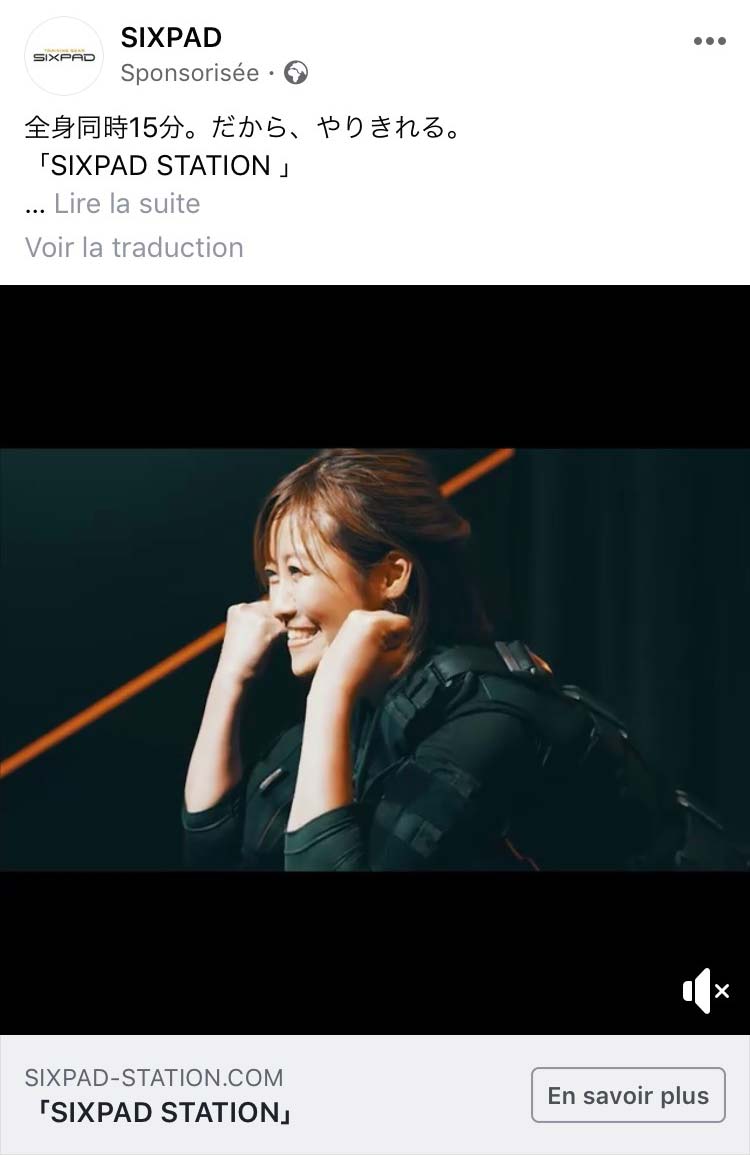 Cette publicité s’est affichée le jour même où je confiais à un proche avoir envie de reprendre le sport car j’avais l’impression de perdre mes abdominaux. Nous avions alors parlé de notre volonté de faire de l’exercice quand cette publicité pour les électrodes musculaires Sixpad est apparue. Une fois encore, aucune recherche web pour justifier un tel affichage. La seule source de renseignement possible étant notre échange verbal.
Cette publicité s’est affichée le jour même où je confiais à un proche avoir envie de reprendre le sport car j’avais l’impression de perdre mes abdominaux. Nous avions alors parlé de notre volonté de faire de l’exercice quand cette publicité pour les électrodes musculaires Sixpad est apparue. Une fois encore, aucune recherche web pour justifier un tel affichage. La seule source de renseignement possible étant notre échange verbal.
 Le jour même où je confiais à ma compagne avoir un peu mal au dos en raison d’une mauvaise posture au travail, Facebook propose soudainement ces publicités pour une compagnie de massages au Japon. Nous n’en n’avons plus reparlé, la publicité n’est plus jamais revenue.
Le jour même où je confiais à ma compagne avoir un peu mal au dos en raison d’une mauvaise posture au travail, Facebook propose soudainement ces publicités pour une compagnie de massages au Japon. Nous n’en n’avons plus reparlé, la publicité n’est plus jamais revenue.
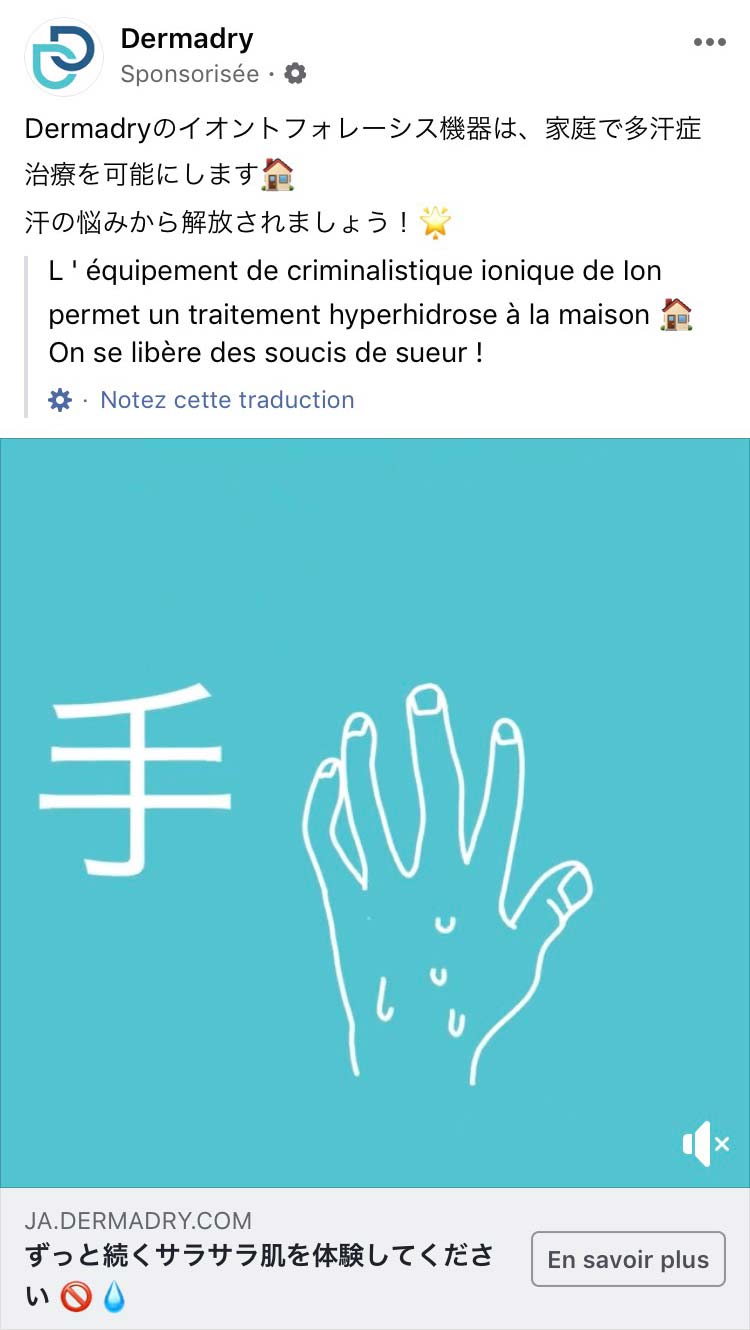 Probablement le cas le plus mystérieux et révélateur à nos yeux tant le besoin concerné est spécifique et rare. C’est ce cas qui nous a poussés à écrire notre article. Un jour de conduite, je dis à un proche, oralement toujours, que mes mains sont trop humides et que c’est assez gênant pour conduire. Le soir même, cette publicité d’une entreprise spécialisée contre la sueur excessive – dont l’image cible spécifiquement les mains – apparaît dans mon fil d’actualité… Une fois encore, aucune recherche internet à ce sujet, la problématique étant ponctuelle. Nous n’aurons plus jamais cette publicité à l’avenir.
Probablement le cas le plus mystérieux et révélateur à nos yeux tant le besoin concerné est spécifique et rare. C’est ce cas qui nous a poussés à écrire notre article. Un jour de conduite, je dis à un proche, oralement toujours, que mes mains sont trop humides et que c’est assez gênant pour conduire. Le soir même, cette publicité d’une entreprise spécialisée contre la sueur excessive – dont l’image cible spécifiquement les mains – apparaît dans mon fil d’actualité… Une fois encore, aucune recherche internet à ce sujet, la problématique étant ponctuelle. Nous n’aurons plus jamais cette publicité à l’avenir.
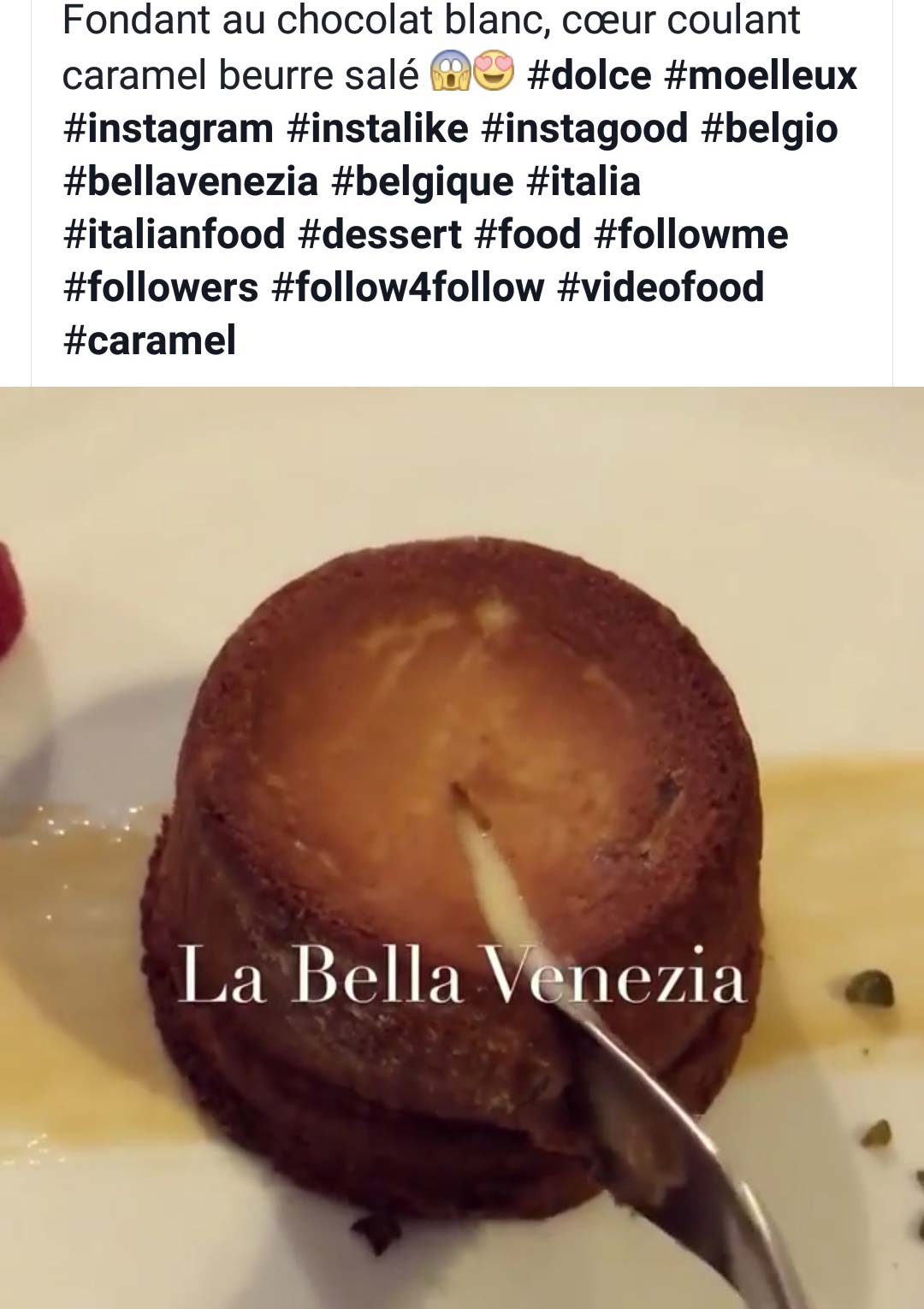
Ici, une démonstration des limites du système. Nous avions parlé de notre souhait de visiter Venise (Venezia en anglais) quand cette publicité pour des viennoiseries de Venise sont apparues. Il est probable que la marque concernée utilise le mot « Venise » pour cibler ses clients. Comme toujours, aucune recherche web sur le sujet.
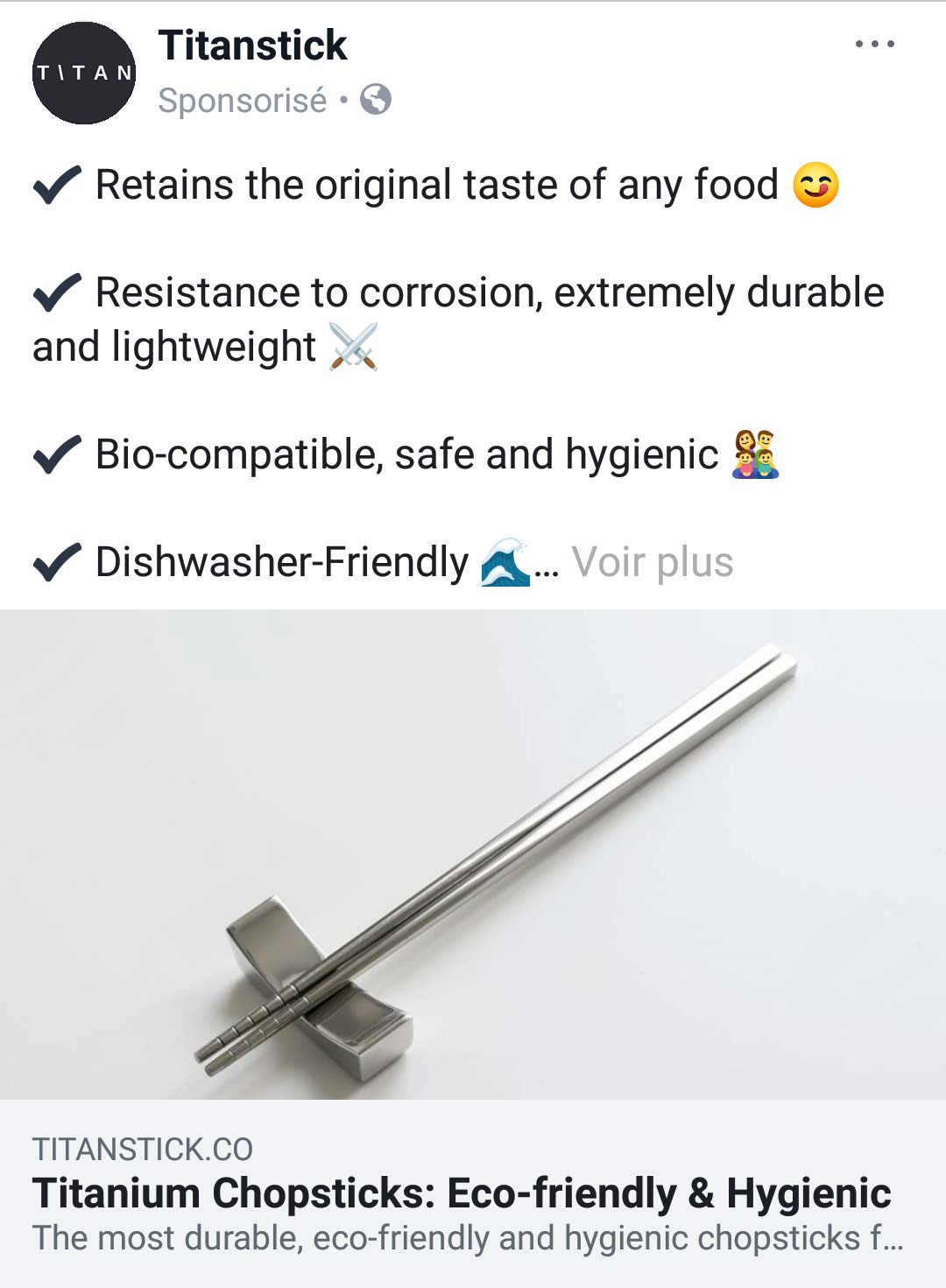
Autre cas troublant et très spécifique. Un ami me confie oralement dans un lieu extérieur vouloir trouver des baguettes métalliques à acheter. Cette-ci sont apparues dans mon fil d’actualité quelques temps après ! Ce n’est pas le genre de produit qui passe dans une actualité sans un sponsoring très bien ciblé.

Autre erreur et approximation du système utilisé. Nous avions discuté avec un ami francophone de la possibilité de produire des bijoux en métal. Le mot métal (en français) fut largement utilisé pendant notre conversation. Le lendemain, cette publicité pour de la musique Metal apparaissait. Probablement une confusion entre les langues (métal/metal = prononciation proche). Je n’écoute plus de Metal depuis mon adolescence (probablement à tort!).
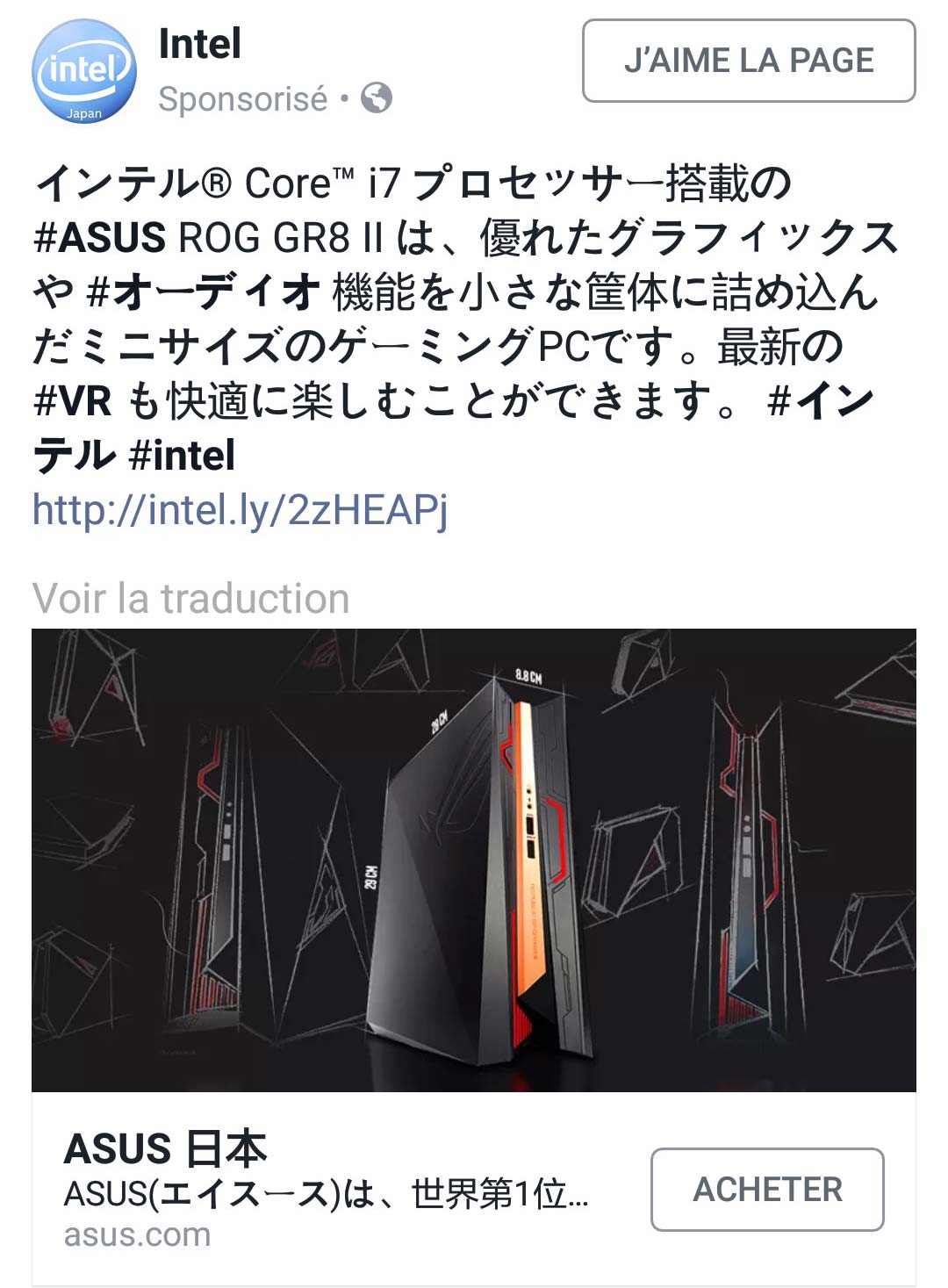
À nouveau, l’envie verbale d’acheter un nouvel ordinateur de qualité professionnelle – notamment pour le travail et le montage vidéo – a donné lieu à l’apparition de ce genre de publicité avant même avoir effectué une quelconque recherche.

Et notre tout premier cas concret. Nous discutions avec un ami de l’importance d’avoir au moins un costume de travail de qualité au Japon. Dans les 24 heures, cette publicité ciblée apparaissait dans notre fil d’actualité. Nous n’aurons plus jamais de publicité pour des costumes par après.
Observations générales :
– La récurrence excessive du phénomène a tendance à confirmer l’hypothèse d’une écoute active des conversations. La récurrence excessive laisse peu de place au hasard, tant les chances de coïncidence sont infinitésimales.
– Les erreurs manifestes de l’écoute ont davantage tendance à confirmer l’écoute. En particulier, le cas du « Metal » relève une faille dans la détection et la compréhension des mots dans leur sens pratique. On peut émettre l’hypothèse que l’algorithme d’écoute ne fait qu’associer des mots-clés entre eux pour les offrir sur le marché des annonceurs classiques.
– Le phénomène se produit sur certaines périodes de temps et dans certaines conditions qu’il me fut impossible d’isoler précisément. Ce qui implique que l’écoute est temporaire, non pas continue, liée à des situations qu’il conviendrait d’étudier plus précisément. Il n’est pas impossible que la technique soit encore en phase de test pratique.
– Le fait d’être au Japon lors de ce test rend difficile la généralisation des résultats à d’autres pays du monde.
– Si le test s’est limité à une utilisation de Facebook, rien n’indique que l’écoute provienne de Facebook. Le marché de l’échange de l’information étant tentaculaire et interconnecté, il est possible qu’une application tierce soit à l’origine de l’enregistrement. Les données récoltées peuvent être revendues et échangées entre acteurs de l’information en quelques secondes.
– Se savoir enregistré ne doit pas générer de la paranoïa pour autant. Rien n’indique que cette écoute soit utilisée dans un autre but que de nous vendre des choses dont nous n’avons pas forcément besoin. Aucun complot ni machination complexe là-dedans. Du simple business as usual.
Conclusion
À nos yeux, il n’existe plus aucun doute sur le fait qu’une écoute active des utilisateurs à des fins commerciales et à leur insu soit une réalité très concrète en 2020. Rien n’interdit techniquement à certains géants de l’information ou sociétés spécialisées de récolter et exploiter ces données. Cependant, il n’est pas possible de déterminer si cette écoute active est continuelle ou temporaire, si elle fut l’objet de tests ponctuels ou si elle est pratiquée à large échelle sur toutes formes d’appareils. Une chose est certaine, les témoignages des utilisateurs sont légion.
Dans tous les cas, nous estimons que les consommateurs devraient en être informés et avoir le choix de refuser d’être sur écoute de manière continuelle. La position des géants de l’information de nier cette réalité nous apparaît hautement problématique. Nous invitons également les médias et observateurs à faire preuve de prudence avant de se référer exclusivement aux communiqués des GAFAM et d’études de sociétés privées. Nous rappelons que le marché des données privées et du web-marketing pèse plus de 300 milliards de dollars avec la promesse d’atteindre les 500 milliards d’ici 2023 seulement. Des chiffres qui donnent le tournis. À ce titre, l’accès à vos informations privées vaut de l’or en barre pour ceux qui sauront y accéder et les exploiter. Non, se contenter d’analyser vos recherches ne suffit certainement plus à satisfaire l’appétit des investisseurs du secteur, d’autant plus que la technique est relativement basique à mettre en place et que la mise en concurrence les force à avancer dans cette direction sans cadre légal restreignant. Ne jamais perdre de vue cette réalité quand quelqu’un met en doute la possibilité d’être écouté en permanence dans un but commercial.







voir Perfect Blue, grand classique de l’animation japonaise")





